
AI Insights
Why AI Development is Different: The Role of Experimentation in Data Science


Recent advancements have significantly heightened business interest in AI, making it accessible to literally everyone. Just a few years ago, only trained data scientists had the expertise to predict oil futures or develop chatbots.
Now, with tools like AutoML and easy-to-use APIs for generative AI, nearly anyone can create a machine learning model or an AI-driven chatbot prototype. However, while using off-the-shelf tools to address standard business problems seems appealing, the journey from a prototype to a production-ready AI solution is often long and complex, requiring the specialised skills of data scientists to ensure success.
Data Science vs. Software Development: Two Different Lifecycles
Software development follows a mostly linear and predictable path known as software development lifecycle (SDLC): from gathering requirements and planning, through development, to testing and deployment. From the start, both the team and stakeholders have a clear vision of the end product, defined success criteria, and confidence that achieving these goals is possible. The focus is typically on managing time and effort to reach the finish line.
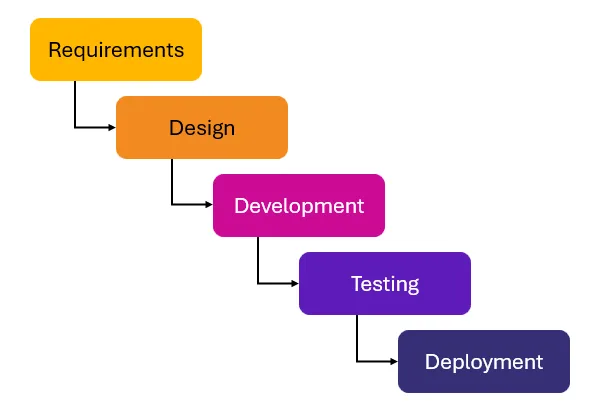
By contrast, AI development requires a far more iterative and exploratory approach. There is less certainty about the timeline and quality of results. Often it is even hard to say whether getting the desired quality is possible until the research is started. The lifecycle of AI projects involves frequent loops, constant adjustments and often – refinements of initial requirements.
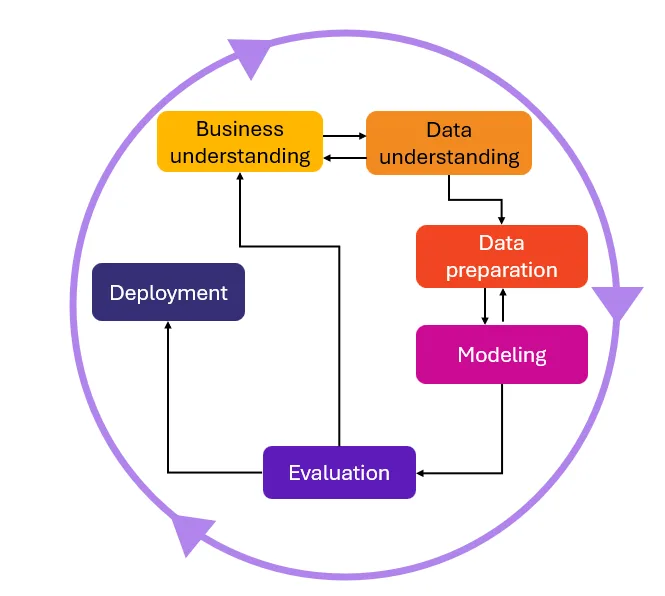
It breaks down into six stages:
1. Understanding the Business Problem: The process begins by defining business needs, selecting data sources, and establishing success metrics (both business and Data Science metrics). Importantly, AI models can’t promise perfect accuracy, so choosing the right evaluation metrics is crucial.
2. Data Collection and Analysis: In this stage, data is gathered and analysed. Often, exploratory data analysis (EDA) may reveal that the data lacks meaningful features or strong patterns, forcing the team to rethink data sources or even redefine project goals.
3. Data Preparation and Feature Engineering: Before modelling can begin, data must be cleaned and transformed. These steps are vital, as poor data preparation can doom a project from the start.
4. Modelling: Model development needs a scientific mindset: start with an objective, explore possibilities iteratively, and refine until a viable solution emerges. Data scientists often begin with a basic model and initial set of features, evaluate outcomes, and then experiment to improve performance. This could mean collecting more data, cleaning it differently, engineering new features, testing alternative models, or optimising hyperparameters. The process is highly exploratory, with many iterations and discarded options along the way.
5. Evaluation: Models are tested on unseen data. If performance doesn’t meet expectations, the team may loop back to previous steps, refining until the model meets the success criteria.
6. Deployment: Only after testing the model at different data sets, understanding its quality and stability, ensuring that pricing, resource consumption and processing time comply with requirements, the model can be deployed.
The Importance of Experimentation
Unlike software development, where tasks follow a clear roadmap, the journey of building an AI solution is cyclical, marked by numerous experiments. AI development demands trying out different approaches, and success only becomes apparent after several iterations and refinements. Skipping the experimentation phase and solving the task with just one approach would almost certainly mean a loss in accuracy. Only through multiple iterations it is possible to get the best performance or efficient resource use.
Key Areas and Benefits of Experimentation
1. Data Processing: Experimenting with data preparation methods is critical for improved data quality, selecting optimal standardization approaches, enhancing model performance and preventing overfitting.
2. Feature Engineering: Creating new, meaningful features can boost predictive power, leverage domain knowledge, simplify models and improve its interpretability.
3. Modelling: Testing different algorithms and parameters leads to optimized decision-making, flexibility in adapting to changing data or requirements, robustness in various scenarios, resource efficiency and establishing a baseline for future improvements.
At each stage, there are multiple options and only through comparing combinations of data processing, feature engineering and modelling techniques, it is possible to get the best results. Thus, spending additional time and effort on experimenting means the success of investment for the business.
The key rule of experiments in Data Science is fairness. Careful preparation of training, validation and test samples means that there is no bias or data leakage in the data sets. All experiments should be run on the very same data sets as this is a condition for a fair comparison of algorithms and approaches. The experimentation stage always ends with a report that contains a summary of all experiments which indicates the best results and suggests the course of actions.
Reporting is a cornerstone of the data science experimentation process. A well-documented report clarifies every decision at each stage of AI development, making the project understandable to stakeholders and future team members. Reports provide a record of what was tested and why, helping teams learn from failures and celebrate successes. If exploration showed that achieving desired results is impossible, the report would contain proper justification for the stakeholders and a starting point for future development. By summarising the outcomes, the report can guide future iterations and help set realistic expectations for what’s achievable.
For example, for one of our clients, Godel’s Data Science team developed a pipeline for detecting keyword stuffing in content. The report included a few sections including:
- Project summary: goals, stages of development, expected results,
- Definition of keyword stuffing: summary of discussions with stakeholders about deciding on the definition and types of keyword stuffing that the model should detect,
- Influence analysis: analysis of project influence on other projects,
- Exploratory data analysis: analysis of available data, distribution plots, statistical tests for selecting promising features, feature engineering,
- Modelling: information about data used for modelling, logic of train-test split, steps of data preparation, established baseline results, a summary of all the models tried out, calculated metrics,
- Aggregated score definition: formulas and explanations of the logic of an aggregated score for multiple keyword stuffing types along with examples,
- Estimation: comparison of metrics for different keyword stuffing types, examples of corner cases, explanations of results for stakeholders, estimation at full data sample, idea of real-life situation with keyword stuffing of the content, simulation of statistics with different thresholds,
- Deployment summary: schemas of pipelines, schedule of re-training and inference, information on required resources and tunning time, format and example of the output with explanation,
- Information on usage of output: queries for getting the pipeline output from the database, links to the dashboards with up-to-date analytical information on keyword stuffing.
Conclusion
Working with AI needs not only a different set of tools compared to software development but also a different mindset. The nature of the Data Science process is in experimenting which allows us to compare multiple approaches, incrementally increase the quality of the solution and build the best algorithm – or prove that achievement of requirements is impossible. Ideally, all the experiments are carefully documented by the data science team to prove every choice in approach at any stage. Skipping the experimentation stage means reaching the lowest hanging fruit – it can work well for a prototype stage but when a production-ready model the team would face multiple challenges starting from inadequate quality and ending with inefficient resource usage.
Katsiaryna Ruksha, Lead Data Scientist
Posted 13 Dec 2024
Read more AI Insights
-

-
Learn more
Godel accelerating digital delivery with Awaze ahead of peak demand
-
Lead Java Software Engineer, Siarhei Dvaradkin
Learn moreChange Propagation: SDD’s Central Unsolved Challenge
-
Siarhei Oshyn, Head of Data / Data & AI Architect
Learn moreWhat LLM will be the best choice for your business?
-
Valdemaras Girštautas, Jr, JavaScript Software Engineer
Learn morePrompt Context Types: Key Experimental Findings
-
Learn more
Godel helps Welbeck Health turn AI ambition into action




