
Joe Wolski, CTO
Prompt Engineering: Classification of Techniques and Prompt Tuning



Being an emerging field of study prompt engineering lacks definitive classification of techniques. When you look through different articles and websites discussing these techniques, you’ll find that they vary and lack structure. As a result of this mess, practitioners often stick to the simplest approaches. In this article I propose an overview and a clear classification of prompt engineering techniques that will help you grasp their concepts and use them effectively in your applications. Additionally, I’ll talk about conducting prompt engineering as a Data Science process that involves prompt tuning and evaluation.

Despite many researches’ efforts, large language models still struggle with some issues. Their major pitfalls are:
Most prompt engineering techniques address two issues: hallucinations and solving math and commonsense tasks. There are specific techniques that aim to mitigate prompt hacking but this is a topic for separate discussion.
Before discussing the specific techniques, let’s talk about common rules of prompting that will help you to write clear and specific instructions:
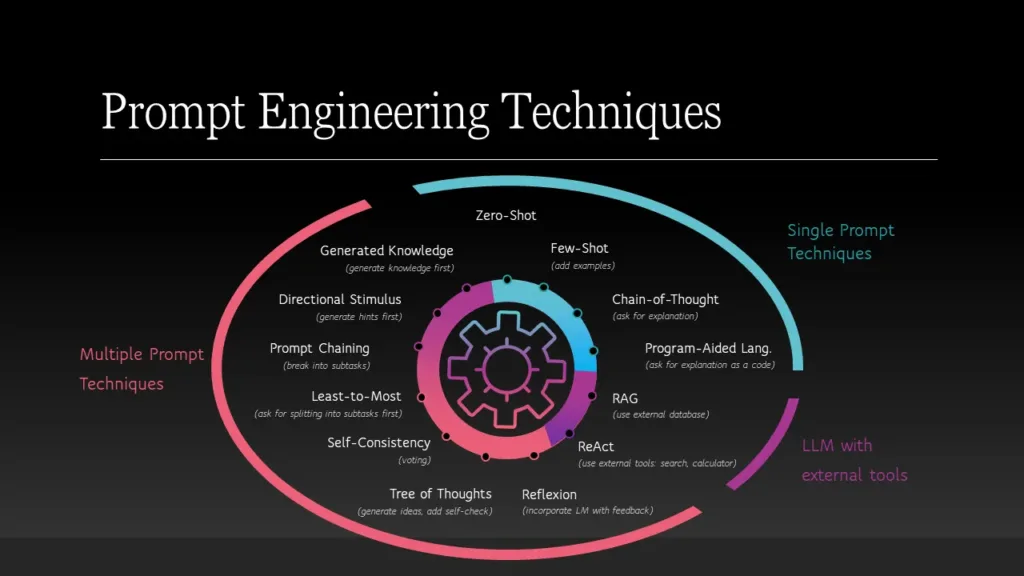
Most of existing techniques can be divided into three groups:

What techniques aim to solve your task in a single prompt?
Let’s study them one by one.
This is the simplest technique that uses natural language instructions.

LLMs are extremely good at one-shot learning but they still may fail at complicated tasks. The idea of few-shot learning is to demonstrate to the model similar tasks with correct answers (Brown et al. (2020)).

In Min et al. (2022) paper, it is shown that incorrectness of labels of demonstrations barely hurts the performance on a range of classification
and multi-choice tasks. Instead, it’s essential to ensure that demonstrations provide a few examples of the label space, the distribution of the input test and the overall format of the sequence.
Chain-of-Thought prompting enables complex reasoning capabilities through intermediate reasoning steps. This technique aims to make the model iterate and reason each step.

CoT is used either with zero-shot or few-shot learning. The idea of Zero-shot CoT is to suggest a model to think step by step in order to come to the solution. Authors of the approach (Kojima et al. (2022)) demonstrate that Zero-shot-CoT significantly outperforms zero-shot LLM performances on arithmetic, symbolic and other logical reasoning tasks.
If you select Few-shot CoT, you must ensure to have diverse examples with explanations (Wei et al. (2022)). The empirical gain of the approach is striking for arithmetic, commonsense, and symbolic reasoning tasks.
Program-Aided language models is an approach that extends Chain-of-Thought prompting by extending the explanation as a natural language with code (Gao et al. (2022)).

The technique can be implemented using LangChain PALChain class.
The next group of prompts is based on different strategies of combining prompts of one or a few of models:
Self-consistency is based on the intuition that “a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer” (Wang et al. (2022)).
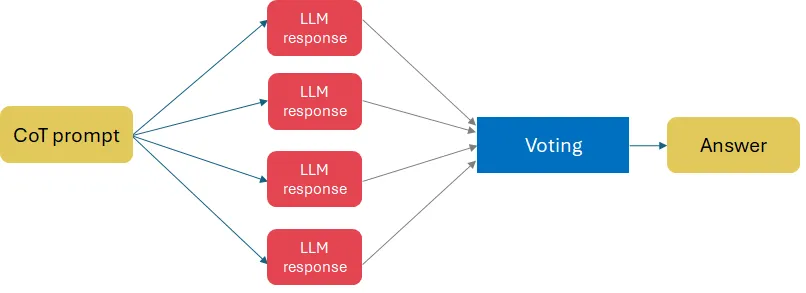
It asks the same Chain-of-Thought prompt a few times thus generating a diverse set of reasoning paths and then select the most consistent answer by applying voting.

In Wang et al. (2022) the gain of applying self-consistency for arithmetic and commonsense tasks was 4%–18% on common benchmarks.
Next concept for combining prompts is “Divide and Conquer”. In DSP we have two steps: generate stimulus (e.g., keywords) and use them to improve quality of the response.
Directional Stimulus prompting was proposed in Li et al. (2023) for summarization, dialogue response generation, and chain-of-thought reasoning tasks. It includes two models:

The policy model can be optimized through supervised fine-tuning using labeled data and reinforcement learning from offline or online rewards based on the LLM’s output, for example:

The next prompting technique under the “Divide and Conquer” concept is Generated Knowledge proposed in Liu et al. (2022). The idea is to use a separate prompt to generate the knowledge first and then use it to get a better response.
Generated knowledge prompting involves two stages:

The method does not require task-specific supervision for knowledge integration, or access to a structured knowledge base, yet it improves performance of large-scale, state-of-the-art models on commonsense reasoning tasks.

Prompt chaining is simple yet powerful technique in which you should split your task into subproblems and prompt the model with them one by one.
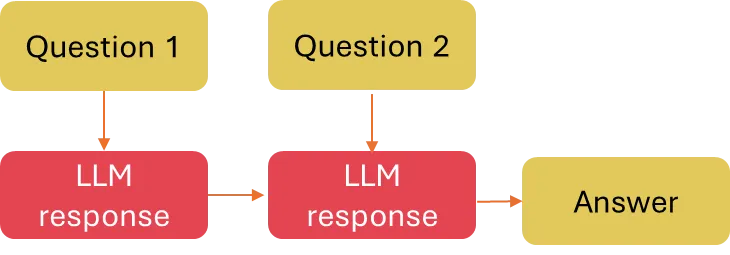
Prompt chaining is useful to accomplish complex tasks which an LLM might struggle to address if prompted with a very detailed prompt. It also helps to boost the transparency of an LLM application, increases controllability, and reliability.

Least to Most prompting goes a little bit further adding a step where a model should decide on how to split your task into subproblems.

Experimental results in in Zhou et al. (2022) reveal that least-to-most prompting is performing well on tasks related to symbolic manipulation, compositional generalization, and math reasoning.

In the recent study (Wang et al. (2024)) a new approach is proposed where tabular data is explicitly used in the reasoning chain as a proxy for intermediate thoughts.
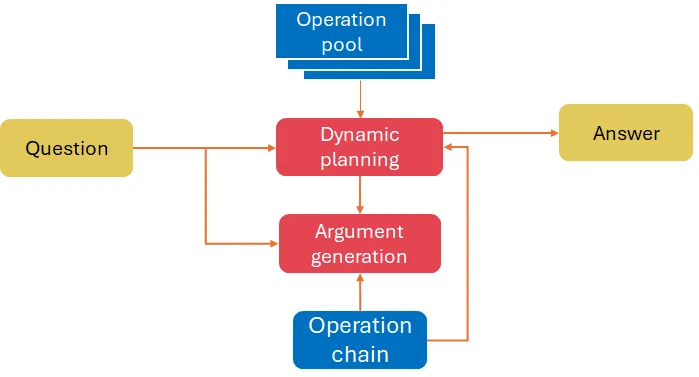
The algorithm includes a cycle of two steps:
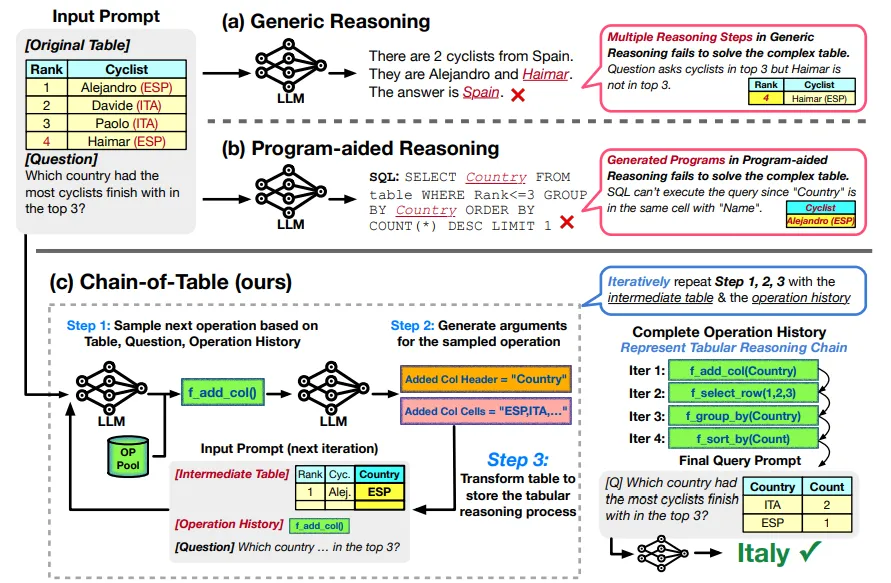
The next two approaches implement the concept of Self-Check — there’s a step in the framework that checks the solution. Example of Cgain-of-Table implementation can be found by the link.
Tree of Thoughts generalizes over the Chain-of-Thought approach allowing the model to explore multiple reasoning steps and self-evaluate choices.
To implement ToT technique, we must decide on four questions:

The input prompt must include description of the intermediate steps to solve the problem and either sampled thoughts, or instructions on their generation. The state evaluator prompt must provide instructions on which prompts to select for the next step.
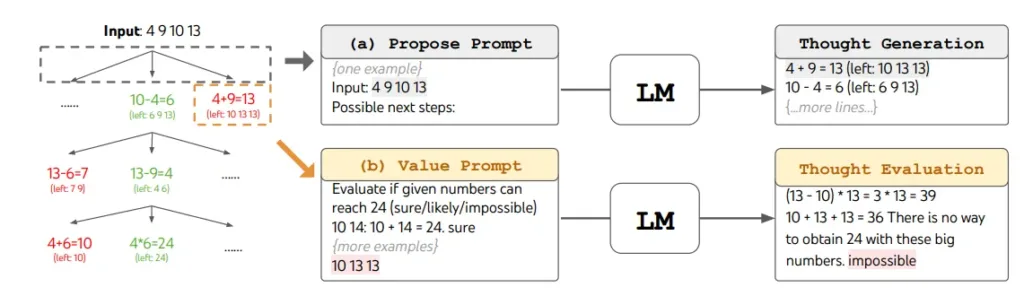
Experiments in Yao et el. (2023) show success of the ToT for tasks requiring non-trivial planning or search. The LangChain has implementation of Tree-of-Thought technique in langchain_experimental.tot.base.ToTChain class.
Reflexion is a framework that reinforces language agents through linguistic feedback. Reflexion agents verbally reflect on task feedback signals, then maintain their own reflective text in an episodic memory buffer to induce better decision-making in subsequent trials (Shinn et al. (2023)).
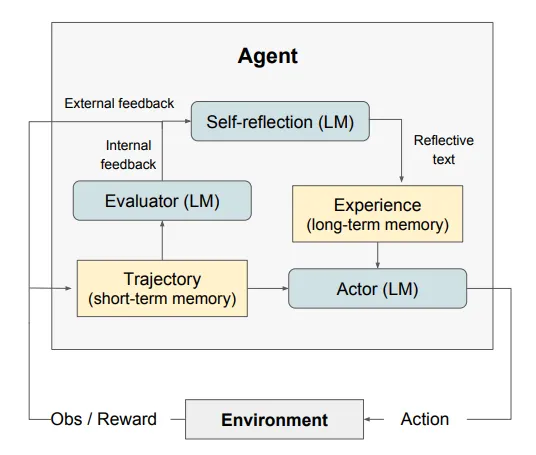
Reflexion framework consists of three distinct models:

Reflexion performs well in tasks that require sequential decision-making, coding, language reasoning.
Check out the implementation by the link.
I’ll cover two approaches in this section — Retrieval Augmented Generation and ReAct.
Retrieval-Augmented Generation (RAG)
RAG combines an information retrieval component with a text generator model:
In most cases RAG-sequence approach is used meaning that we retrieve k documents, and use them to generate all the output tokens that answer a user query.
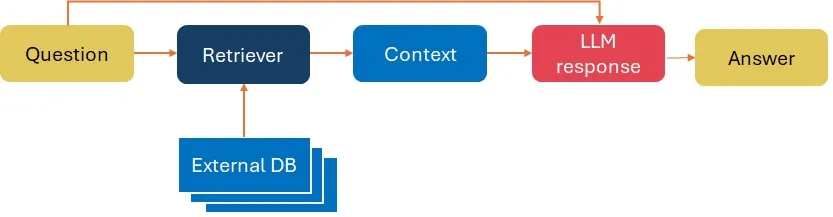
Language models in RAG can be fine-tuned but in reality it’s rarely done as pre-trained LLMs are good enough to use as is, and too costly to fine-tune ourselves. Moreover the internal knowledge in RAG can be modified in an efficient manner and without needing retraining of the entire model.

RAG generates responses that are more factual, specific, and diverse, improves results on fact verification.
Yao et al. (2022) introduced a framework named ReAct where LLMs are used to generate both reasoning traces and task-specific actions in an interleaved manner: reasoning traces help the model induce, track, and update action plans as well as handle exceptions, while actions allow it to interface with and gather additional information from external sources such as knowledge bases or environments.

ReAct framework can select one of the available tools (such as Search engine, calculator, SQL agent), apply it and analyze the result to decide on the next action.

ReAct overcomes prevalent issues of hallucination and error propagation in chain-of-thought reasoning by interacting with a simple Wikipedia API, and generating human-like task-solving trajectories that are more interpretable than baselines without reasoning traces (Yao et al. (2022)).
Check out an example of ReAct implementation with Langchain tools.
Choice of prompt engineering technique highly depends on the application of your LLM and resources available. If you ever experimented with a prompt you know that large language models are sensitive to the smallest changes in human-generated prompts which are suboptimal and often subjective.
No matter what prompting technique you select, if you are building an application it’s very important to think of prompt engineering as of a Data Science process. This means creating a test set and choosing metrics, tuning the prompts and evaluating its influence on the test set.

Metrics for testing a prompt will to high extent depend on the application but here are some guidelines (from Data Science Summit 2023):

2. Retrieval — for RAG and ReAct pipelines mainly but can be applied to generated knowledge and directional stimulus prompting:
3. Internal thinking:
4. Non-functional:
Depending on your use case, select metrics and track influence of your prompt changes on the test set ensuring that any change doesn’t degrade quality of the responses.
I don’t claim to have covered all the existing techniques — there are so many of them that soon someone will publish a whole textbook. But if you read that far, you’ve noticed that the concepts of all the techniques are quite common and intuitive. I can summarize all the rules of writing a good prompt into a small list:
Joe Wolski, CTO





Sr. JavaScript Software Engineer Robert Oleksza