
AI Insights
Productionising Modern AI/ML Solutions with Kubeflow: A Platform-Level Approach


Modern AI solutions are becoming increasingly complex. Models must not only be trained but also retrained automatically, monitored for accuracy, and scaled under load. None of this is possible without AI/ML Ops – a set of practices and tools that make AI/ML solutions manageable, reliable, and reproducible. In one of our recent blog series, we discussed the key components of AI Solutions Architecture, mentioning Kubeflow as one of the platforms that simplifies AI model deployment and maintenance.
Source: kubeflow.org
In this article, we go one step further. We share how Kubeflow helped us bring AI/ML solutions into production:
- Why delivering AI requires more than just good models and where MLOps fits in.
- What makes Kubeflow suitable for building production-grade ML/AI systems.
- What you can actually do with Kubeflow and how it helps operationalise AI workflows.
- How we prepared engineers to use Kubeflow confidently.
We’re sharing real engineering experience to help teams and businesses better understand how to deliver and maintain production-grade AI systems.
Why AI/ML Solutions Fail Without MLOps
When businesses talk about AI, they often imagine a smart model that instantly adds value – predicting trends, analysing data, and supporting decisions. And in the early stages, that might be true. A Data Scientist builds a model, someone deploys it manually, and the results look promising.
But then reality kicks in.
- A month later, the data has shifted, and the model’s accuracy starts to degrade.
- Developers step in to retrain and redeploy it – manually.
- Each update takes days, sometimes weeks, with no clear way to compare old and new versions.
- There’s no monitoring, no rollback strategy, and little confidence in long-term stability.
For small businesses or pilot projects, this manual approach might be enough. But as the product grows, more users, data, pressure and the lack of process become a real blocker. Teams start building their own AI/ML Ops frameworks, burning time and budget just to keep the system afloat.
In some cases, companies quietly shut down promising AI initiatives, not because the model was bad, but because they couldn’t maintain it. The value is lost, and AI gets a reputation as an expensive toy.
That’s where ML Ops comes in. Just like DevOps revolutionised software delivery, MLOps provides the foundation for stable, automated, and scalable machine learning in production.
- Models retrain automatically.
- Performance is monitored continuously.
- Versions are tracked and rolled back if needed.
- Engineers spend less time on manual work, and more time improving the product.
And this is exactly what Kubeflow enables: turning AI/ML Solution into something real, reliable, and production-ready without building the entire stack from scratch.
- It reduces the risk of AI investment failure by ensuring models don’t get abandoned halfway due to lack of support.
- It shortens the go-to-market time through automation, repeatable workflows, and scalable infrastructure.
- And it saves teams from reinventing the wheel, giving them a solid foundation for AI/ML Ops, right out of the box.
Why Kubeflow?

Source: kubeflow.org
When a company starts working with AI, the inevitable question arises: where to train and deploy models? Many turn to ML/AI platforms offered by industry giants like AWS, Azure, or GCP.
These platforms cover a wide range of needs, from model training and deployment to versioning, monitoring, and integration with other services. For many teams, they provide a fast and reliable way to get started.
However, when it comes to long-term strategy, there are important factors to consider.
The topic of cost always comes up, and for good reason. But there’s no universal answer. Without a concrete business case and implementation scenario, it’s impossible to say whether one platform is cheaper or more expensive than another. That’s why we won’t make general claims. Instead, we’ll focus on what we can prove from experience.
One key consideration is vendor lock-in. Once your solution is deeply integrated into a cloud ecosystem, migrating to another environment becomes difficult and expensive. This can limit flexibility and slow down innovation. That’s where Kubeflow comes in.
It’s an open-source AI/ML platform that runs on Kubernetes and is fully infrastructure-agnostic. You can deploy it in the cloud, on-premises, or in a hybrid setup depending on your needs.
You’re not paying for the platform itself, only for the infrastructure you choose. And if that infrastructure is already in place, there’s no vendor lock-in or duplicated costs. This makes it clear and predictable from a business standpoint.
Kubeflow provides full control over the machine learning lifecycle:
You can build pipelines, retrain models, manage versions, monitor performance, and customize every step. It’s particularly valuable when AI is not a prototype but a strategic business function.
And while it’s built on Kubernetes, the entry barrier is surprisingly low. In our experience, engineers with basic DevOps skills were able to get started with Kubeflow faster than with some fully managed platforms like Amazon SageMaker.
That said, Kubeflow isn’t a plug-and-play solution and is not a magic button. More advanced use cases – CI/CD integration, multi-environment deployment, production-grade scaling – require a solid engineering foundation.
But what makes this open-source AI/ML platform especially strong is the community.
Kubeflow is not a side project, it’s a living ecosystem. With over 13,000 GitHub stars, hundreds of contributors, and regular releases, it continues to grow alongside the AI/ML Ops landscape. That means teams benefit not just from open access, but from a network of practitioners and shared knowledge.
At a high level, it sounds promising. But what does it actually look like in practice? Let’s take a look under the hood.
What can you do with Kubeflow? (Functionality without Overcomplication)
Kubeflow is designed to support the entire AI/ML solution lifecycle, from initial experiments to serving and continuous monitoring. What sets it apart is how its components align with real-world workflows, providing structure and flexibility without unnecessary complexity.
Let’s walk through what you can do with Kubeflow, step by step.
Experiment and Explore
Kubeflow includes Jupyter Notebooks, which let data scientists explore datasets, prototype models, and run early-stage tests – all within the platform and connected to shared storage and Kubernetes resources.
As experiments become more structured, Katib helps automate hyperparameter tuning. It supports multiple optimization algorithms and runs experiments in parallel, making it easier to find the best-performing configuration.
This early stage combines interactive experimentation with structured testing – giving engineers the tools they need to move from idea to prototype, with traceable results.
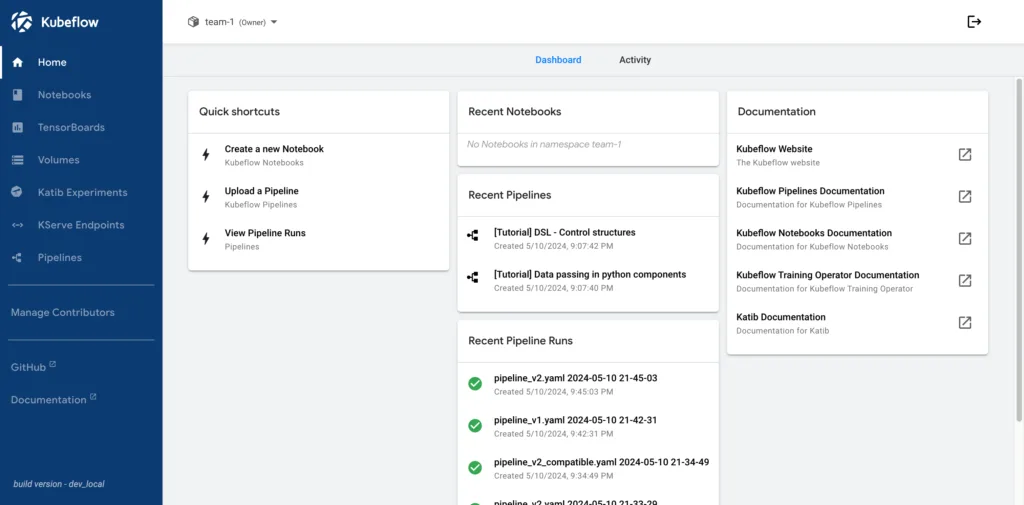
Automate Pipelines
When you move beyond notebooks, Kubeflow Pipelines (KFP) let you define multi-step ML workflows using Python or YAML. These pipelines can include data preparation, training, validation, evaluation, and deployment. They’re versioned, visualised in the UI, and support conditional logic, parallel execution, and parameterisation.
Each run is tracked automatically, including inputs, outputs, and metadata. This helps teams understand how models are built and enables reproducibility – a core requirement in production environments.
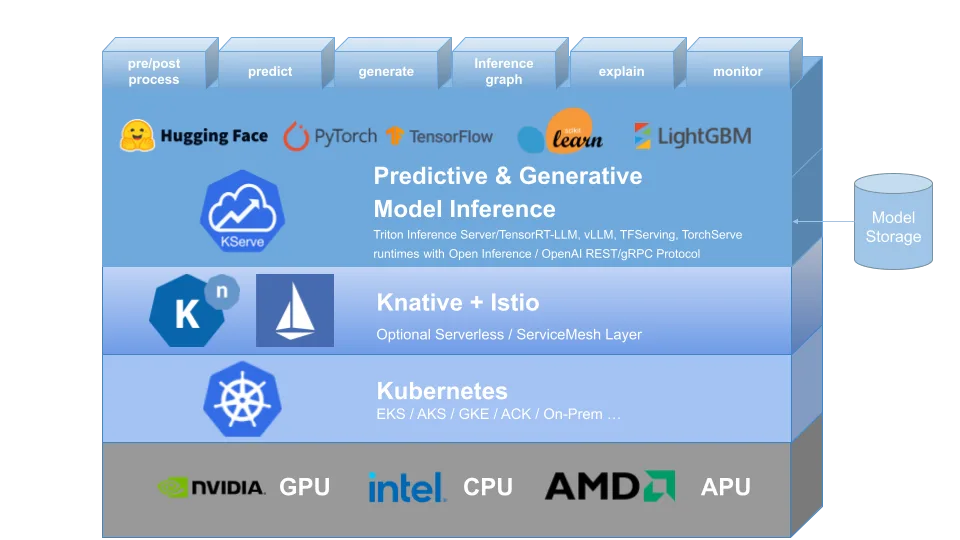
Deploy Models
For inference, Kubeflow uses KServe (formerly KFServing). It supports real-time and batch inference, works with popular AI/ML frameworks like TensorFlow, PyTorch, and ONNX, and includes autoscaling based on traffic. KServe also supports canary rollouts and model versioning – essential for safe updates in production.
Monitor and Observe
Monitoring is critical when models move to production. While Kubeflow doesn’t ship with its own monitoring stack, it integrates well with Prometheus, Grafana, and service mesh tools like Kiali. Together, these tools provide visibility into inference latency, error rates, data drift, and system performance – allowing teams to detect degradation early.
Some teams also integrate MLflow for specific use cases. For example, to log experiments across different environments, manage model versions in a central registry, or reuse existing pipelines built around MLflow APIs. Kubeflow already covers most tracking needs at the pipeline and experiment level. But for full production-grade observability, including system-wide metrics, alerting, and dashboards, teams usually integrate tools like Prometheus and Grafana.
Automate Retraining
With Recurring Runs, you can schedule retraining pipelines: weekly, daily, or based on external triggers. This allows teams to keep models up to date as data evolves, without manual intervention. Each scheduled run produces new versions and logs its results – helping you track the lifecycle of every model.
Modular and Practical
Kubeflow doesn’t aim to hide the complexity of AI/ML Ops. Instead, it gives you well-designed components to manage that complexity in a clear, modular way. Whether you’re working on a proof of concept or building a scalable AI product, you can use the same tools and scale them as needed.
It’s not a magic button, but a practical system that helps teams do AI/ML Ops right without locking themselves into a specific cloud provider or black-box platform.
Kubeflow in Practice: Challenges and Learnings
Source: kubeflow.org
Many companies today reach a similar point: they’ve built an AI prototype, maybe even validated it with real users — and now face the next big question: How do we move this to production, quickly and reliably?
That’s where our engineering team often steps in, helping clients bridge the gap between MVP and a production-grade AI solution. And Kubeflow is one of the key platforms we use for that.
One of our recent projects involved a high-load, search-driven platform where machine learning wasn’t just an enhancement it was essential. Up-to-date models were required for relevance, matching, and recommendations. Without retraining and automation, the user experience would degrade rapidly.
Instead of building everything from scratch, we used Kubeflow as the backbone for the production pipeline:
- Training workflows were built using Kubeflow Pipelines — versioned, traceable, and repeatable.
- Model deployment was handled via KServe, enabling autoscaling and safe rollouts.
- Monitoring and logs helped us detect failures early and validate retraining effectiveness.
- Scheduled retraining ensured the model stayed aligned with fresh data with no manual triggers.
This allowed us to shorten time-to-production significantly. The client got a robust, modular ML platform without the overhead of developing their own AI/ML Ops framework.
Kubeflow isn’t a silver bullet, it still requires engineering effort. But in our experience, the learning curve is manageable, and the return is real. It shortens time-to-market, reduces technical debt, and gives teams full control over the model lifecycle. It’s not just about “running models.” It’s about helping teams build AI solutions that survive in production.
How We Promote Kubeflow? (MLOps Lab)
At Godel, we have a dedicated role – the AI/ML Ops Engineer, a cross-functional professional combining the skills of a data engineer and system integrator. And one of their key missions is to make AI solutions work reliably in production.
Learning Kubeflow internally was just the first step.
We wanted to go further to help more engineers gain the knowledge and confidence to use Kubeflow not just as a toy, but as a platform for real-world, production-grade AI.
That’s how the MLOps Lab was born. Our internal training program built around real business cases and hands-on tasks. Instead of theoretical exercises, it focuses on common production scenarios teams face when working with ML systems.
Each topic focuses on a practical challenge teams face in production environments, such as batch inference, automated retraining, model redeployment, LLM integration, and serving Retrieval-Augmented Generation (RAG) pipelines.
The goal is to teach not just how Kubeflow works, but how to use it to build and maintain AI systems that last: handle model drift, automate updates, validate outputs, and debug issues, all within one platform.
By the end of the lab, engineers don’t just know what Kubeflow is, they know how to run real AI/ML products on top of it.
Conclusion
Who and when should use Kubeflow?
Source: kubeflow.org
Let’s say it again – Kubeflow is not a magic button. It’s a platform for teams that want full control over the AI/ML I lifecycle, from experiments to deployment, retraining, and monitoring.
If your goal is to quickly launch an AI prototype without managing infrastructure, cloud platforms are often the faster route. But if AI is central to your product, and you need custom workflows, automation, and transparency, Kubeflow is worth your attention.
We help teams productionise AI solutions: automate pipelines, monitor model performance, and build processes that scale.
But building models is just part of the story. Without clean, governed data – even the best ML system will struggle. That’s why we always emphasise data quality, harmonisation, and clear ownership alongside model operations.
Kubeflow gives you the building blocks. We help you assemble them into a system that works in production.
In the end, it’s not about choosing a “better tool.” It’s about choosing the one that fits your business goals and making it work.
Valiantsin Shkvarko, Data Architect and Viktoryia Bolbas, Senior MLOps Engineer
Posted 13 May 2025
Read more AI Insights
-

-
Learn more
Godel accelerating digital delivery with Awaze ahead of peak demand
-
Lead Java Software Engineer, Siarhei Dvaradkin
Learn moreChange Propagation: SDD’s Central Unsolved Challenge
-
Siarhei Oshyn, Head of Data / Data & AI Architect
Learn moreWhat LLM will be the best choice for your business?
-
Valdemaras Girštautas, Jr, JavaScript Software Engineer
Learn morePrompt Context Types: Key Experimental Findings
-
Learn more
Godel helps Welbeck Health turn AI ambition into action




